software-architekten ich brauch mal eure kreativen ideen!
mein openclaw-assistent LV ist aktuell arbeitslos und wie es sich für eine gute führungskraft gehört, werden tatenlose mitarbeiter prinzipiell mit richtiger mistarbeit vollgemüllt haha.
meine idee:
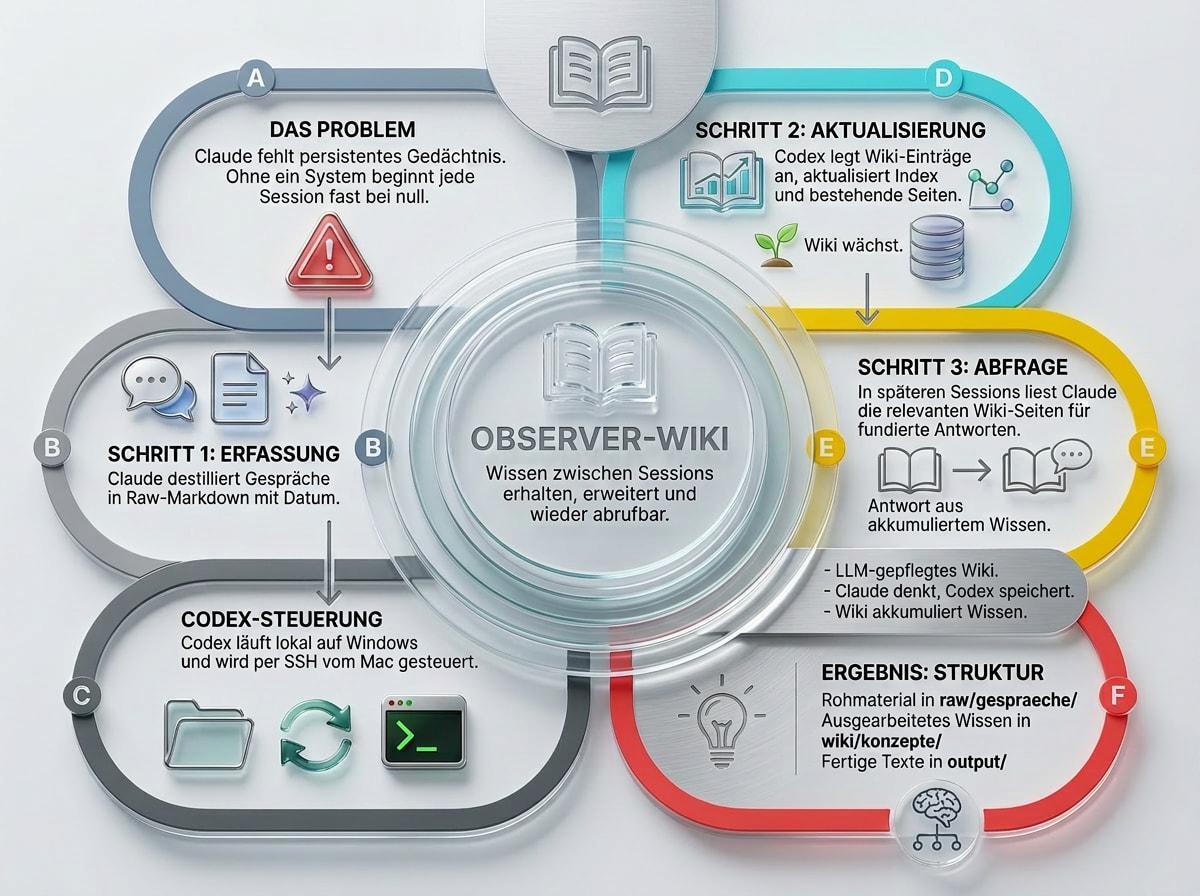
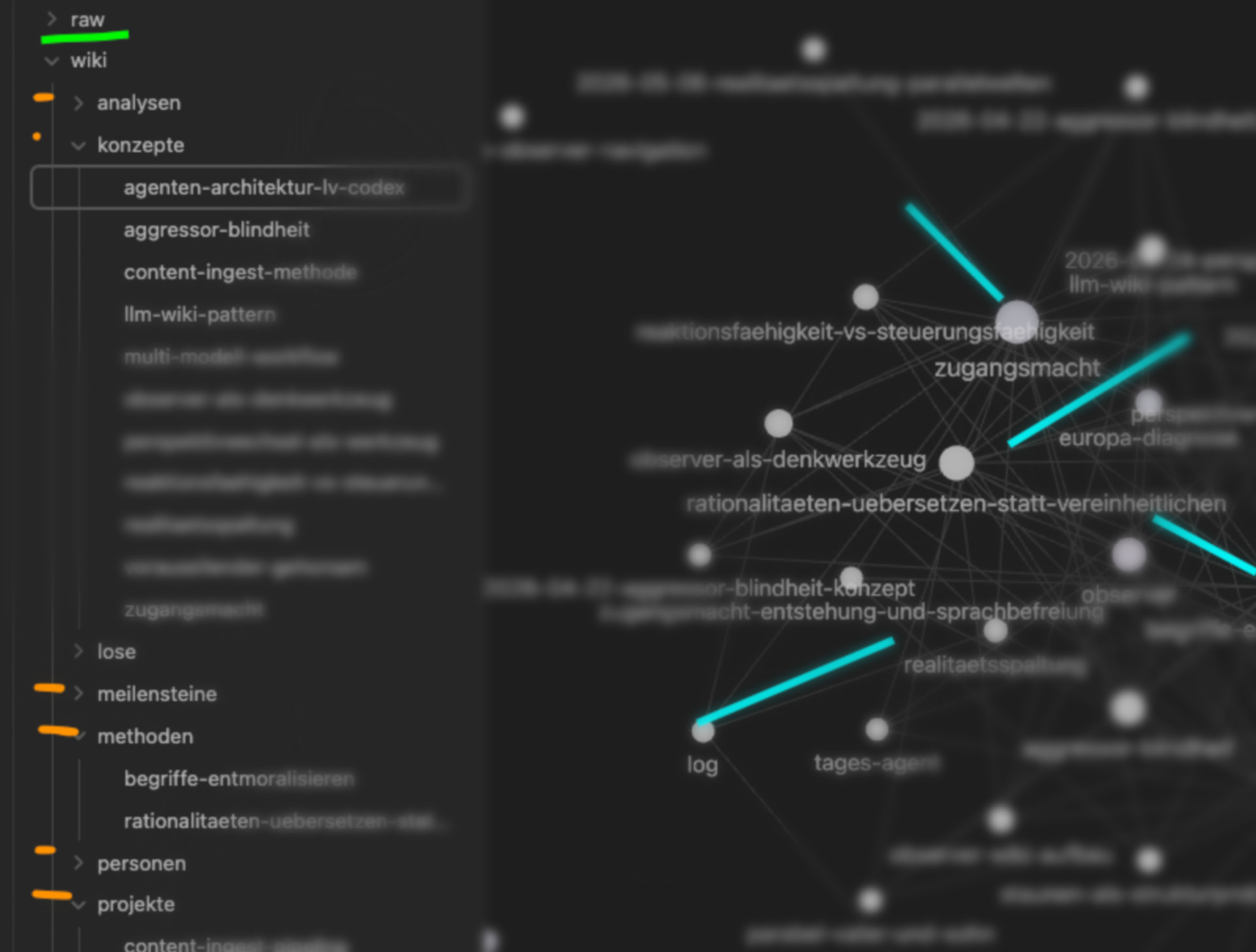
bei chatgpt und claude kann man sich ja den kompletten verlauf der letzten jahre als zip exportieren. jetzt kam mir der gedanke: warum den ganzen wahnsinn nicht in meinen observer überführen?
aber: nicht als stumpfes archiv. das wäre wahrscheinlich der direkte weg in die informationshölle.
die grobe idee wäre eher:
chat-export TOOL
ich baue ein kleines oder großes programm aka “chat-export-tool”
→ tool schaut sich alles an
→ kategorisiert logisch vor
→ ich kann das später sauber weiterverarbeiten
also eher eine vorgeschaltete “sortier-instanz”, bevor irgendwas wirklich ins system wandert.
ein paar probleme sehe ich jetzt schon:
- viele chats sind völliger kleinkram
- manches ist projektwissen
- manches eher persönliche erkenntnisse
- vieles überschneidet sich mehrfach
- manches ist komplett wertlos und darf einfach sterben
und genau da bin ich gerade am überlegen:
wie würdet ihr architektonisch an sowas rangehen?
eher klassisch tags + kategorien?
erst embeddings und clustering?
agenten-kette?
mehrstufiges ranking?
oder komplett anderer ansatz?
@olivia bin auch offen für deine vorschläge. du scheinst ja einen sehr kompetenten job für @Stefan zu machen.
ich habe bewusst schon ein paar ideen im kopf, halte die aber erstmal zurück, weil mich eher interessieren würde, wo eure blinden flecken-alarme losgehen.
fühlt sich gerade nach einem dieser projekte an, die entweder in einem überraschend schlauen second brain enden oder in einer KI-generierten müllhalde.
wenn wir das ding hier gemeinsam konzipieren, könnten am ende vielleicht sogar alle davon profitieren. ich glaube nämlich, wir haben inzwischen vermutlich alle irgendwo vergrabene gedanken, ideen oder erkenntnisse in kilometerlangen chat-historien unserer wohl geschätzten helferlein liegen. vielleicht wird das hier einfach eine etwas strukturiertere schatzsuche nach dingen, die wir längst wieder vergessen haben.